


At Bhoos, our Marriage app was scaling up: more and more new users every day, more features every week and more games every quarter. Through this, one issue has always proved a pain (in the databases): synchronization. Earlier methods seemed to work reasonably well, given a little debugging and very little stress testing when we had fewer users. But as the traffic and load grew, the architecture we had started buckling under the pressure. In response, we have had to devise a new design from the ground up, one that took inspiration from more theoretically-sound methods but tweaked for our own needs. We’ll first take a look at the issues that plagued our earlier implementation, what ideas we considered for improvements and finally, where we are at now with the new all-in-one app that hosts multiple games.
The Crudeness of CRUD
Like most modern-day applications, we started with CRUD, implemented through REST APIs. (To read more about why we’re moving away from REST, go through this post). When we implemented offline play, the problems started. To allow users to play completely offline, we had the following setup.
- Allow users to accumulate changes locally for features that work offline (e.g. single player).
- Store a differential state in the client (i.e. the app) that is separated into
deltaandupdate: Deltastores changes for values that are accumulative, e.g. players’ coins or count of games played.Updatestores changes for values that are meant to be replaced, e.g. timestamp for when the user last played or being awarded an achievement.- During sync, first send this differential state from client to server through an API.
- The server takes these changes and merges them with the player’s state (stored in the database).
- The server sends back the user’s entire state to the client, overwriting whatever the client previously had stored.
You might already have an inkling of what issues could arise. The primary one was this - outside of server logs, we did not have a way of looking at the history of each user, especially to figure out how an afflicted user could have an illegal or corrupt state. Even with server logs (expensive to maintain and difficult to parse through at volume), since we accumulated all changes locally into a single object, often client apps would send us some fragmented state that did not make sense. This was exacerbated when we shipped bugs. It was not easy to cleanly isolate the effects of buggy code, and near impossible to retroactively fix users’ states later on.
To add to this, our latencies were rising. At one point we crossed an average of 150 ms for the sync endpoint. Issues often affected the users who had a larger payload to sync, in effect, our most fervent fans were getting the shortest end of the stick. Sending the entire state from server to client for every sync request was also expensive and felt unneeded, yet there was no easy alternative. Aside from the architecture itself, we also hadn’t considered some edge cases that required row-locking to prevent subtle transaction failures that included the same sync packet being processed multiple times.
We had multiple requirements for an ideal solution. Offline synchronization was the main problem, and multi-device support was non-negotiable. Aside from that, performance optimization, a central source of truth and a mechanism decoupled (and resilient to) from feature implementation and the resulting bugs were our secondary priorities.
Data (re)Structuring
Rule 5. Data dominates. If you've chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming. - Rob Pike’s 5 Rules of Programming
From our massive online migration earlier (read more), we had already gotten a bitter taste of jsonb and how unsuitable data structures are, in a lot of ways, the heart of the problem. To be able to look at a player’s history, we needed to be able to store, step by step, each of their actions. Simply being concerned with the end state of the user was not enough. The first step needed was to have atomic and sequential actions that could be saved as a proxy for the user’s intent. This would allow us to debug the state of a player’s account through time, as well as have the added benefit of being able to reconstruct a player’s state if they were affected by any critical bugs.
The Figma blog post on how they implemented multiplayer sync is an excellent read on this topic. We took inspiration from the CRDTs mentioned, as well as the CQRS pattern and event-sourced systems to think up our own solution.
The current architecture roughly resembles the figure below.
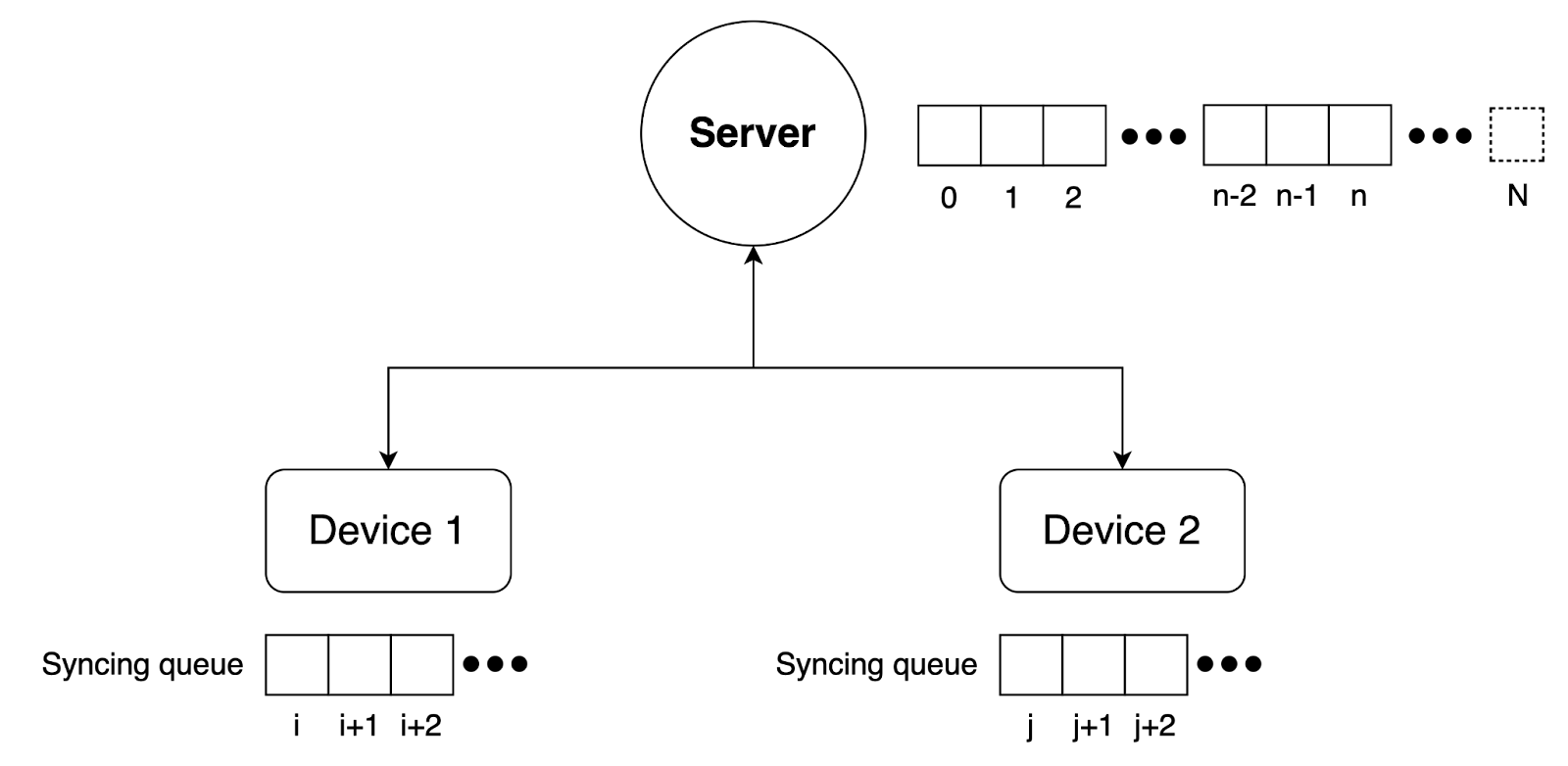
The core of the synchronization mechanism revolves around both client devices and the server maintaining action queues. Actions are defined as serializable objects that have the necessary information to advance a state forward into the next one.
- Client queues store unsynced actions, i.e. actions that the user has generated (and is permitted to do so) offline that have not yet been accepted by the server.
- Server queue stores (if necessary) the actions that have been accepted (whether generated server-side or client-side) and have been incorporated into the state.
The state of a player’s account is still stored in the database. We turned to Redis, in particular the new streams feature to implement a queue with a at-least-once pub/sub implementation baked in. Conceptually, all client devices of a user are simply consumers of this global queue, with actions being sent to them as they get accepted into the queue.
The syncing process works roughly as indicated by the diagram below, which illustrates the lifecycle of an action.
Actions can also be considered as implementations of the command pattern. As soon as a client device creates an action, it adds the metadata of the device id as well as a device sequence number. A number of such client actions are sent to the server when the client is online, packaged in a sync API. The server then processes these actions, either accepting or rejecting them. Rejection reasons could be inconsistencies or attack preventions (e.g. rejecting actions that say provide a user with a million diamonds). The processing of client actions is sequential and transactional so that state inconsistencies are prevented. The server also attaches a server sequence number to the action’s metadata. All user states start at the same initial state, with a sequence number of 0, and thus progress sequentially forward, accumulating changes.
While we do avoid frequent state-sending by this mechanism, one concern was that if a client stayed offline for an extremely long period of time, we might need to send thousands of actions to it. This issue is easily circumvented by the realization that we can define an arbitrary size N such that the server should instead send the state if: actions to send > N. Thus, although conceptually the server should have all the actions (and we do store actions separately similar to logs), in practice it simply maintains a cache of N recent actions as best it can, and sends state to the client if the actions are not present. In this model, the clients are eventually consistent when they come online and finish the syncing process. Clients also maintain two states: one unsynced that is used as the basis for the app, and a synced state that is only advanced by verified, server-sent actions. The clients are able to rebase (similar to git) if they receive actions that they did not create by storing these two states and examining the sequence number of the actions.
Designing stupid solutions
This newly reformulated architecture is not perfect, of course. A number of issues popped out immediately, and we turned to the tried and tested methodology of designing stupid solutions. For instance, we solved many issues of conflict resolution by avoiding such conflicts altogether.
One early issue was how to solve achievements. If you have played 99 games on your account, and we provide an achievement worth X diamonds for playing 100 games, you could play the 100th game offline on two separate devices and claim achievements on both, getting 2X diamonds in the process. We simply decided to have features like achievement and reward unlocks, which are a part of the game economy, be online-only. Only after a successful API completion are such actions inserted by the server, avoiding the aforementioned irregularities altogether. In the same vein, we separated singleplayer and multiplayer currencies, to prevent most shenanigans (it’s not the biggest deal to let people spend offline currency that they don’t have).
Another issue was race conditions: if two devices simultaneously generate actions, in what order do we accept them? Timestamps seemed excessive and fault-prone, and people could always change the datetime of their devices. Here too, a simple solution presented itself: the server would simply process actions in the order it received them, and that would be the correct order. Some other conflicts have been avoided by preventing illegal states such as having negative currency and coalescing such values to zero instead.
Challenges
This new synchronization setup is not a quick and easy fix, unfortunately. While from this post it may seem that CRUD is evil and stupid, it is also quite easy to work with and simple. Rather, we simply hit the limitations of what CRUD and the data structures we had previously employed could accomplish, and our needs widened. Below are some challenges that are ahead of us now.
- Complexity has been increased, both on server side and client side. We now need to maintain queues and maintain two different states on the client side. At the server side as well, we need stricter transactional and locking mechanisms, and horizontal scalability is impacted by the need for all servers to be connected and coordinating.
- Actions might seem like simple serializable pieces of data, but designing actions well is now a serious challenge. If we are to provide backwards compatibility and not force our users to update their apps frequently, actions need to be preemptively extensible and maintainable. Mistakes such as incorrect implementation of state reducers or database procedures are made correctable by the new architecture, as long as the actions have been implemented correctly.
- In line with complexity, there is now a lot more room for testing and tuning. This is perhaps the hardest part, since older test suites are rendered obsolete and our new test mechanisms need to be stateful from the get go. Performance improvements have already been observed, yet we’re not sure where we’ll be hitting our limits as this system is stress tested in production.
We still have a long way to go, and are currently writing test suites and debug tools that take advantage of player histories now being available. Yet the new architecture is already providing dividends in terms of predictability, transparency and controllability. In conclusion, it is never too late to rethink how you do things and to deviate from the baseline, especially as your needs scale.